Apache Spark currently supports two approaches to streaming: the “classic” DStream API (based on RDDs), and the newer Dataframe-based API (officially recommended by Databricks) called “Structured Streaming.” As I have been learning the latter API it took me a while to get the hang of grouping via time windows, and how to best deal with the interplay between triggers and processing time vs. event time. So you can avoid my rookie mistakes, this article summarizes what I learned through trial and error, as well as poking into the source code. After reading this article you should come away with a good understanding of how event arrival time (a.k.a. processing time) determines the window into which any given event is aggregated when using processing time triggers.
A MOTIVATING USE Case
To motivate the discussion, let’s assume we’ve been hired as Chief Ranger of a national park, and that our boss has asked us to create a dashboard showing real time estimates of the population of the animals in the park for different time windows. We will set up a series of motion capture cameras that send images of animals to a furry facial recognition system that eventually publishes a stream of events of the form:
<timestamp>,<animalName>,count Each event record indicates the time a photo was taken, the type of animal appearing in the photo, and how many animals of that type were recognized in that photo. Those events will be input to our streaming app. Our app converts those incoming events to another event stream which will feed the dashboard. The dashboard will show — over the last hour, within windows of 10 minutes — how many animals of each type have been seen by the cameras — like this:
1 PM - 2 PM
13:00 - 13:15
fox: 2
duck: 1
bear: 4
13:15 - 13:30
duck: 9
goat: 1
13:30 - 13:45
bear: 1
dog: 1
13:45 - 14:00
dog: 1
cat: 2Initially Incorrect Assumptions About How The Output Would Look
As a a proof-of-concept, our streaming app will take input from the furry facial recognition system over a socket, even though socket-based streams are explicitly not recommended for production. Also, our code example will shorten the interval at which we emit events to 5 seconds. We will test using a Processing Time Trigger set to five seconds, and the input below, where one event is received every second.
Note: for presentation purposes the input events are shown broken out into groups that would fit within 5 second windows, where each window begins at a time whose ‘seconds’ value is a multiple of five. Thus the first 3 events would be bucketed to window 16:33:15-16:33:20, the next five to window 16:33:20-16:33:25, and so on. Let’s ignore the first window totals of rat:3,hog:2 and come back to those later.
event-time-stamp animal count
2019-06-18T16:33:18 rat 1 \
2019-06-18T16:33:19 hog 2 =>> [ 33:20 - 33:25 ]
2019-06-18T16:33:19 rat 2 / rat:3,hog 2
2019-06-18T16:33:22 dog 5
2019-06-18T16:33:21 pig 2
2019-06-18T16:33:22 duck 4
2019-06-18T16:33:22 dog 4
2019-06-18T16:33:24 dog 4
2019-06-18T16:33:26 mouse 2
2019-06-18T16:33:27 horse 2
2019-06-18T16:33:27 bear 2
2019-06-18T16:33:29 lion 2
2019-06-18T16:33:31 tiger 4
2019-06-18T16:33:31 tiger 4
2019-06-18T16:33:32 fox 4
2019-06-18T16:33:33 wolf 4
2019-06-18T16:33:34 sheep 4Our trigger setting causes Spark to execute the associated query in micro-batch mode, where micro-batches will be kicked off every 5 seconds. The Structured Streaming Programming Guide says the following about triggers:
If [a] … micro-batch completes within the [given] interval, then the engine will wait until the interval is over before kicking off the next micro-batch.
If the previous micro-batch takes longer than the interval to complete (i.e. if an interval boundary is missed), then the next micro-batch will start as soon as the previous one completes (i.e., it will not wait for the next interval boundary).
If no new data is available, then no micro-batch will be kicked off.
Given our every-5-second trigger, and given the fact that we are grouping our input events into windows of 5 seconds, I initially assumed that all our batches would align neatly to the beginning of a window boundary and contain only aggregations of events that occurred within that window, which would have given results like this:
Batch: 0
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |3 |
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|hog |2 |
+------------------------------------------+------+------------+
Batch: 1
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|duck |4 |
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|dog |13
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|pig |2 |
+------------------------------------------+------+------------+
Batch: 2
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|horse |2 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|mouse |2 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|lion |2 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|bear |2 |
+------------------------------------------+------+------------+
Batch: 3
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|tiger |8 |
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|wolf |4 |
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|sheep |4 |
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|fox |4 |
+------------------------------------------+------+------------+What We Actually Got, And Why It Differed From Expected
The beginner mistake I made was to conflate processing time (the time at which Spark receives an event) with event time (the time at which the source system which generated the event marked the event as being created.)
In the processing chain envisioned by our use case there would actually be three timelines:
- the time at which an event is captured at the source (in our use case, by a motion sensitive camera). The associated timestamp is part of the event message payload. In my test data I have hard coded these times.
- the time at which the recognition system — having completed analysis and classification of the image — sends the event over a socket
- the time when Spark actually receives the event (in the socket data source) — this is the processing time
The difference between (2) and (3) should be minimal assuming all machines are on the same network — so when we refer to processing time we won’t worry about the distinction between these two. In our toy application we don’t aggregate over processing time (we use event time), but the time of arrival of events as they are read from the socket is definitely going to determine the particular five second window into which any given an event is rolled up.
One of the first things I observed was that the first batch consistently only reported one record, as shown below:
Batch: 0
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |1 |
+------------------------------------------+------+------------+In order to understand why the first batch did not contain totals rat:3 and hog:2 (per my original, incorrect assumption, detailed above), I created an instrumented version of org.apache.spark.sql.execution.streaming.TextSocketSource2 which prints the current time at the point of each call to getBatch() and getOffset(). You can review my version of the data source here (the file contains some comments — tagged with //CLONE — explaining the general technique of copying an existing Spark data source so you can sprinkle in more logging/debugging statements.) I also instrumented the program I was using to mock the facial recognition system such that it would print out not only the content of the event payload being sent, but also the time at which the event was written to the socket. This test program is discussed in the next section. The Spark output that I got for first batch was roughly this:
socket read at Thu Jun 20 19:19:36 PDT 2019
line:2019-06-18T16:33:18,rat,1
at Thu Jun 20 19:19:36 PDT 2019 getOffset: Some(0)
at Thu Jun 20 19:19:36 PDT 2019 getBatch: start:None end: 0
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |1 |
+------------------------------------------+------+------------+
socket read at Thu Jun 20 19:19:37 PDT 2019
line:2019-06-18T16:33:19,hog,2The mock facial recognition system was set to emit one event every second, so it printed the following (abbreviated) output for this run:
input line: 2019-06-18T16:33:18,rat,1
emitting to socket at Thu Jun 20 19:19:36 PDT 2019:
2019-06-18T16:33:18,rat,1
input line: 2019-06-18T16:33:19,hog,2
emitting to socket at Thu Jun 20 19:19:37 PDT 2019:
2019-06-18T16:33:19,hog,2Here is an explanation of why we only reported one record in the first batch. When the class that backs the “socket” data source is initialized it starts a loop to read from the configured socket and adds event records to a buffer as they are read in (which in our case is once every second.) When the MicrobatchStreamExecution class invokes our trigger the code block will first invoke constructNextBatch() which will attempt to calculate ‘offsets’ (where the current head of the stream is in terms of the last index into
the buffer of available data), then the method runBatch() will call the getBatch() method of our socket data source, passing in the range of offsets to grab (using the offset calculation in the previous step.)
TextSocketSource.getBatch will cough up for whatever events the read loop had buffered up.
Prior to the the getBatch() call, which occurs at 19:19:36. The only event received prior (at 19:19:36) was rat,1. So this is the only event reported in the first batch. Note that our times are reported in resolution of seconds, so that the rat,1 event was reported as arriving concurrently with the getBatch() call; I am taking it on faith that with finer grained resolutions we would see the time stamp for the ‘socket read ….rat,1’ message be slightly before the timestamp of the first getBatch() call.
In the course of execution of our (5 second) trigger we only make one call to getBatch() at the start of processing, and we pick up the one event that is available at that time. In the time period covered by the first 5 second trigger other events could be arriving over the socket and getting placed into the buffer ‘batches’. But those events won’t be picked up until the next trigger execution (i.e., the subsequent batch.) (Please see the final section of the article for a diagram that illustrates these interactions.)
We provide a listing showing the actual batch results we obtained, below.
Batch: 0
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |1 |
+------------------------------------------+------+------------+
Batch: 1
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|duck |4 |
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|dog |5 |
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |3 |
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|pig |2 |
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|hog |2 |
+------------------------------------------+------+------------+
Batch: 2
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:20, 2019-06-18 16:33:25]|dog |13 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|horse |2 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|mouse |2 |
+------------------------------------------+------+------------+
Batch: 3
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|tiger |8 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|lion |2 |
|[2019-06-18 16:33:25, 2019-06-18 16:33:30]|bear |2 |
+------------------------------------------+------+------------+
Batch: 4
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|wolf |4 |
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|sheep |4 |
|[2019-06-18 16:33:30, 2019-06-18 16:33:35]|fox |4 |
+------------------------------------------+------+------------+Note that certain time windows take a couple of batch cyles to settle into correctness. An example is the total for dog given for window “2019-06-18 16:33:20 – 2019-06-18 16:33:25” in Batch 1. The total should be 13, and in fact the final dog record seems to come in as of Batch 2, and that batch’s report for |[2019-06-18 16:33:20, 2019-06-18 16:33:25]|dog is correct (13 dog sightings for the period.)
For the purposes of our application this seems quite acceptable. Anyone looking at the dashboard display might see some “jitter” around the totals for a particular time window for a particular animal. Since our original requirement was to show totals in 10 minute windows, and since we know there will be some straggler window totals that require two batches to ‘settle’ to correctness, we would probably want to implement the real solution via a sliding window with window length 10 minutes and slide interval of 10 or 15 seconds which would mean (I’m pretty sure, but can’t claim to have tested) that any incomplete counts for a given window would become correct in that 10 to 15 second interval.
Writing Test Data Over a Socket
The code for our simulated facial recognition component is shown below. It should work fine for you in a Mac or Linux environment (and maybe if you use Cygwin under Windows, but no guarantees.) The test script is bash based, but it actually automtically compiles and executes the Scala code below the “!#”, which I thought was kind of cool.
#!/bin/sh
exec scala "$0" "$@"
!#
import java.io.{OutputStreamWriter, PrintWriter}
import java.net.ServerSocket
import java.util.Date
import java.text.SimpleDateFormat
import scala.io.Source
object SocketEmitter {
/**
* Input params
*
* port -- we create a socket on this port
* fileName -- emit lines from this file ever sleep seconds
* sleepSecsBetweenWrites -- amount to sleep before emitting
*/
def main(args: Array[String]) {
args match {
case Array(port, fileName, sleepSecs) => {
val serverSocket = new ServerSocket(port.toInt)
val socket = serverSocket.accept()
val out: PrintWriter =
new PrintWriter(
new OutputStreamWriter(socket.getOutputStream))
for (line <- Source.fromFile(fileName).getLines()) {
println(s"input line: ${line.toString}")
var items: Array[String] = line.split("\\|")
items.foreach{item =>
val output = s"$item"
println(
s"emitting to socket at ${new Date().toString()}: $output")
out.println(output)
}
out.flush()
Thread.sleep(1000 * sleepSecs.toInt)
}
}
case _ =>
throw new RuntimeException(
"USAGE socket <portNumber> <fileName> <sleepSecsBetweenWrites>")
}
Thread.sleep(9999999 *1000) // sleep until we are killed
}
}To run it, save the script to some path like ‘/tmp/socket_script.sh’, then execute the following commands (Mac or Linux):
cat > /tmp/input <<EOF
2019-06-18T16:33:18,rat,1
2019-06-18T16:33:19,hog,2
2019-06-18T16:33:19,rat,2
2019-06-18T16:33:22,dog,5
2019-06-18T16:33:21,pig,2
2019-06-18T16:33:22,duck,4
2019-06-18T16:33:22,dog,4
2019-06-18T16:33:24,dog,4
2019-06-18T16:33:26,mouse,2
2019-06-18T16:33:27,horse,2
2019-06-18T16:33:27,bear,2
2019-06-18T16:33:29,lion,2
2019-06-18T16:33:31,tiger,4
2019-06-18T16:33:31,tiger,4
2019-06-18T16:33:32,fox,4
2019-06-18T16:33:33,wolf,4
2019-06-18T16:33:34,sheep,4
EOF
bash timeless_socket_emitter.sh 9999 /tmp/socket_script.sh 1The script waits for a connection (which comes from our Structured Streaming app), and then writes one even per second to the socket connection.
SOURCE Code For Streaming Window Counts
The full listing of our streaming window counts example program is provided below, and you can also pull a runnable version of the project from github, here.
package com.lackey.stream.examples.dataset
import java.sql.Timestamp
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.log4j._
import org.apache.spark.sql.execution.streaming.TextSocketSource2
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{DataStreamWriter, OutputMode, Trigger}
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
object GroupByWindowExample {
case class AnimalView(timeSeen: Timestamp, animal: String, howMany: Integer)
val fmt = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss")
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder
.master("local")
.appName("example")
.getOrCreate()
// Here is the trick I use to turn on logging only for specific
// Spark components.
Logger.getLogger("org").setLevel(Level.OFF)
//Logger.getLogger(classOf[MicroBatchExecution]).setLevel(Level.DEBUG)
import sparkSession.implicits._
val socketStreamDs: Dataset[String] =
sparkSession.readStream
.format("org.apache.spark.sql.execution.streaming.TextSocketSourceProvider2")
.option("host", "localhost")
.option("port", 9999)
.load()
.as[String] // Each string in dataset == 1 line sent via socket
val writer: DataStreamWriter[Row] = {
getDataStreamWriter(sparkSession, socketStreamDs)
}
Future {
Thread.sleep(4 * 5 * 1000)
val msgs = TextSocketSource2.getMsgs()
System.out.println("msgs:" + msgs.mkString("\n"))
}
writer
.format("console")
.option("truncate", "false")
.outputMode(OutputMode.Update())
.start()
.awaitTermination()
}
def getDataStreamWriter(sparkSession: SparkSession,
lines: Dataset[String])
: DataStreamWriter[Row] = {
import sparkSession.implicits._
// Process each line in 'lines' by splitting on the "," and creating
// a Dataset[AnimalView] which will be partitioned into 5 second window
// groups. Within each time window we sum up the occurrence counts
// of each animal .
val animalViewDs: Dataset[AnimalView] = lines.flatMap {
line => {
try {
val columns = line.split(",")
val str = columns(0)
val date: Date = fmt.parse(str)
Some(AnimalView(new Timestamp(date.getTime), columns(1), columns(2).toInt))
} catch {
case e: Exception =>
println("ignoring exception : " + e);
None
}
}
}
val windowedCount = animalViewDs
//.withWatermark("timeSeen", "5 seconds")
.groupBy(
window($"timeSeen", "5 seconds"), $"animal")
.sum("howMany")
windowedCount.writeStream
.trigger(Trigger.ProcessingTime(5 * 1000))
}
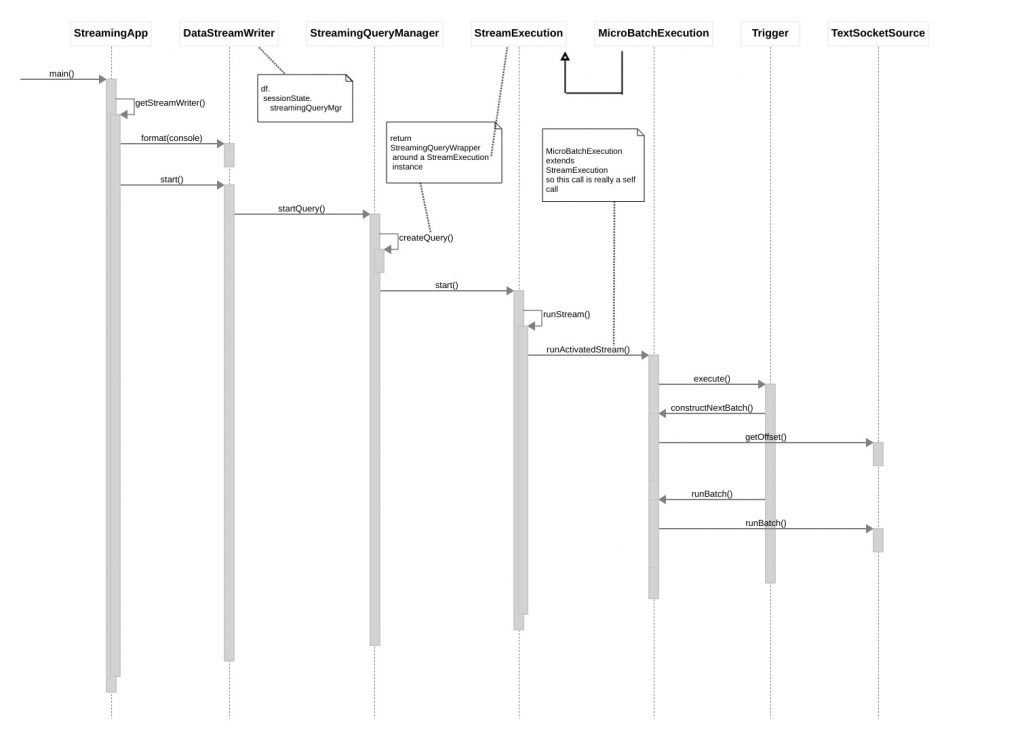
}SPARK & APPLICATION CODE INTERACTIONs
Here is a sequence diagram illustrating how Spark Stream eventually calls into our (cloned) Datasource to obtain batches of event records.